ऐसे कार्यक्रमों के लिए कई विकल्प उपलब्ध हैं जो बड़ी संख्या में सॉकेट कनेक्शन (जैसे वेब सेवाएं, पी 2 पी सिस्टम इत्यादि) को संभालते हैं।बड़ी संख्या में फाइल डिस्क्रिप्टरों को सबसे प्रभावी ढंग से कैसे संभालें?
- प्रत्येक सॉकेट के लिए I/O को संभालने के लिए एक अलग थ्रेड स्पॉन करें।
- I12 को एक थ्रेड में मल्टीप्लेक्स करने के लिए select सिस्टम कॉल का उपयोग करें।
- आई/ओ (चयन को प्रतिस्थापित करने) को मल्टीप्लेक्स करने के लिए poll सिस्टम कॉल का उपयोग करें।
- उपयोगकर्ता/सिस्टम सीमाओं के माध्यम से सॉकेट एफडी को बार-बार भेजने से बचने के लिए epoll सिस्टम कॉल का उपयोग करें।
- कई I/O धागे स्पॉन करें जो प्रत्येक एपीआईपीएल का उपयोग करके कनेक्शन की कुल संख्या का अपेक्षाकृत छोटा सेट मल्टीप्लेक्स करता है।
- प्रत्येक स्वतंत्र I/O थ्रेड के लिए एक अलग एपोल ऑब्जेक्ट बनाने के लिए एपोल एपीआई का उपयोग करके # 5 के अनुसार।
एक मल्टीकोर सीपीयू पर मुझे उम्मीद है कि # 5 या # 6 का सर्वश्रेष्ठ प्रदर्शन होगा, लेकिन मेरे पास इसका समर्थन करने वाला कोई भी कठिन डेटा नहीं है। वेब पर खोज this पृष्ठ पर लेखक परीक्षण दृष्टिकोण # 2, # 3 और # 4 के अनुभवों का वर्णन करने वाला पृष्ठ बदल गया। दुर्भाग्य से यह वेब पेज लगभग 7 साल पुराना प्रतीत होता है, जिसमें कोई स्पष्ट हालिया अपडेट नहीं मिलते हैं।
तो मेरा सवाल यह है कि इनमें से कौन सा दृष्टिकोण लोगों को सबसे कुशल पाया गया है और/या कोई अन्य दृष्टिकोण है जो ऊपर सूचीबद्ध किसी भी से बेहतर काम करता है? वास्तविक जीवन ग्राफ, श्वेतपत्र और/या वेब उपलब्ध लेखन के संदर्भों की सराहना की जाएगी।
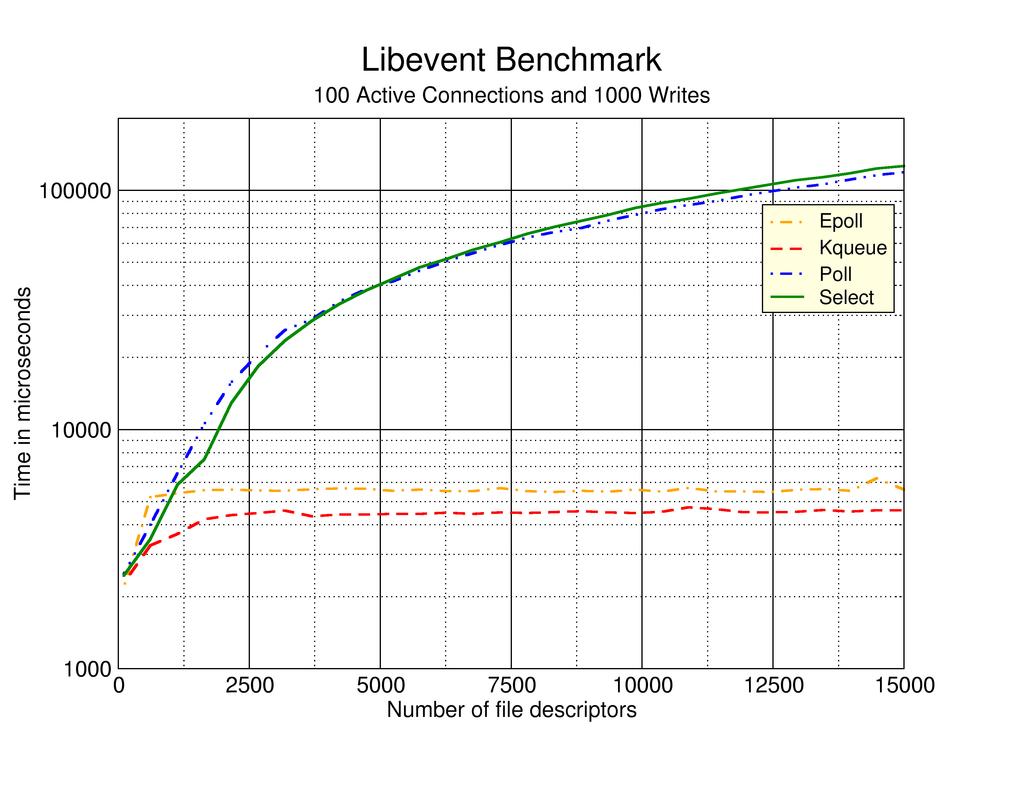 देख पाएंगे।
देख पाएंगे।
मुझे लगता है कि यह एक हल समस्या है और उत्तर यहां है - http://www.kegel.com/c10k.html – computinglife