66
आप में से एक चौड़ाई पहले खोज पथ, का पता लगाने है ऐसी है कि निम्न उदाहरण में:ब्रेडथ-प्रथम खोज में पथ का पता कैसे लगाएं?
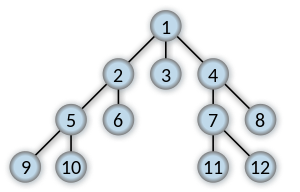
कुंजी 11 के लिए खोज करते हैं, तो कम से कम सूची 1 जोड़ने 11.
[1, 4, 7, 11]
आप में से एक चौड़ाई पहले खोज पथ, का पता लगाने है ऐसी है कि निम्न उदाहरण में:ब्रेडथ-प्रथम खोज में पथ का पता कैसे लगाएं?
कुंजी 11 के लिए खोज करते हैं, तो कम से कम सूची 1 जोड़ने 11.
[1, 4, 7, 11]
आप पहली बार http://en.wikipedia.org/wiki/Breadth-first_search पर नजर है चाहिए।
नीचे एक त्वरित कार्यान्वयन, जिसमें मैं रास्तों में से कतार प्रतिनिधित्व करने के लिए सूची की एक सूची के लिए इस्तेमाल किया है।
# graph is in adjacent list representation
graph = {
'1': ['2', '3', '4'],
'2': ['5', '6'],
'5': ['9', '10'],
'4': ['7', '8'],
'7': ['11', '12']
}
def bfs(graph, start, end):
# maintain a queue of paths
queue = []
# push the first path into the queue
queue.append([start])
while queue:
# get the first path from the queue
path = queue.pop(0)
# get the last node from the path
node = path[-1]
# path found
if node == end:
return path
# enumerate all adjacent nodes, construct a new path and push it into the queue
for adjacent in graph.get(node, []):
new_path = list(path)
new_path.append(adjacent)
queue.append(new_path)
print bfs(graph, '1', '11')
एक और दृष्टिकोण अपनी मूल करने के लिए प्रत्येक नोड से एक मानचित्रण बनाए रखने की जाएगी, और जब आसन्न नोड निरीक्षण, अपनी मूल रिकॉर्ड है। जब खोज पूरी की जाती है, तो मूल मैपिंग के अनुसार बस पीछे हटें।
graph = {
'1': ['2', '3', '4'],
'2': ['5', '6'],
'5': ['9', '10'],
'4': ['7', '8'],
'7': ['11', '12']
}
def backtrace(parent, start, end):
path = [end]
while path[-1] != start:
path.append(parent[path[-1]])
path.reverse()
return path
def bfs(graph, start, end):
parent = {}
queue = []
queue.append(start)
while queue:
node = queue.pop(0)
if node == end:
return backtrace(parent, start, end)
for adjacent in graph.get(node, []):
if node not in queue :
parent[adjacent] = node # <<<<< record its parent
queue.append(adjacent)
print bfs(graph, '1', '11')
ऊपर कोड धारणा कोई चक्र है कि पर आधारित हैं।
यह उत्कृष्ट है! मेरी विचार प्रक्रिया मुझे कुछ प्रकार की टेबल या मैट्रिक्स बनाने में विश्वास करने के लिए प्रेरित करती है, मुझे ग्राफ के बारे में अभी तक सीखना नहीं है। धन्यवाद। –
मैंने बैक ट्रेसिंग दृष्टिकोण का उपयोग करने का भी प्रयास किया हालांकि यह बहुत साफ दिखता है। यदि आप केवल शुरुआत और अंत को जानते हैं लेकिन बीच में नोड्स में से कोई भी नहीं है तो ग्राफ बनाना संभव होगा? या ग्राफ के अलावा एक और दृष्टिकोण? –
@ क्रिस्टोफर एम मैं आपके प्रश्न को समझने में असफल रहा :( – qiao
मैंने सोचा कि मैं मनोरंजन के लिए इस कोड को ऊपर की कोशिश करेंगे:
graph = {
'1': ['2', '3', '4'],
'2': ['5', '6'],
'5': ['9', '10'],
'4': ['7', '8'],
'7': ['11', '12']
}
def bfs(graph, forefront, end):
# assumes no cycles
next_forefront = [(node, path + ',' + node) for i, path in forefront if i in graph for node in graph[i]]
for node,path in next_forefront:
if node==end:
return path
else:
return bfs(graph,next_forefront,end)
print bfs(graph,[('1','1')],'11')
# >>>
# 1, 4, 7, 11
आप चक्र चाहते हैं तो आप इस जोड़ सकते हैं:
for i, j in for_front: # allow cycles, add this code
if i in graph:
del graph[i]
+1, आपने मुझे एक चीज़ की याद दिला दी: 'कोई चक्र नहीं मानें :) :) – qiao
आप कोड का यह टुकड़ा कहां जोड़ देंगे? अगली_for_front बनाने के बाद – Liondancer
। प्रश्न पर एक फॉलो करें, क्या होगा यदि ग्राफ में लूप हों? जैसे अगर नोड 1 में किनारे से जुड़ा हुआ किनारा था? क्या होगा यदि ग्राफ में दो नोड्स के बीच कई किनारों पर जा रहे हैं? –
मैं बहुत ज्यादा qiao का पहला जवाब पसंद आया! यहां गायब होने वाली एकमात्र चीज कशेरुक को विज़िट करने के रूप में चिह्नित करना है।
क्यों हम इसे करने की ज़रूरत है?
[[1, 2, 6], [1, 3, 10], [1, 4, 7], [1, 4, 8], [1, 2, 5, 9], [1, 2, 5, 10]]
नोट:
कल्पना है कि वहाँ एक और नोड संख्या 13 नोड 11. से जुड़े अब हमारे लक्ष्य नोड 13.
एक रन का एक छोटा सा के बाद कतार इस तरह दिखेगा मिल रहा है की सुविधा देता है अंत में नोड संख्या 10 के साथ दो पथ हैं।
जिसका अर्थ है कि नोड संख्या 10 के पथ दो बार चेक किए जाएंगे। इस मामले में यह (यहाँ भी हम बिना किसी कारण के दो बार उस नोड की जाँच करेगा ..) इतना बुरा लग रहा है नहीं नोड संख्या 10 किसी भी बच्चों को नहीं है क्योंकि .. लेकिन क्या यह वास्तव में बुरा हो सकता है
नोड संख्या 13 'isn टी उन पथों में नहीं है, इसलिए कार्यक्रम अंत में नोड संख्या 10 के साथ दूसरे पथ तक पहुंचने से पहले वापस नहीं आएगा .. और हम इसे फिर से जांचेंगे ..
हम जो भी गायब हैं, वे सभी को याद करने के लिए एक सेट है नोड्स और उन्हें फिर से जांच करने के लिए नहीं ..
इस संशोधन के बाद qiao के कोड है:
graph = {
1: [2, 3, 4],
2: [5, 6],
3: [10],
4: [7, 8],
5: [9, 10],
7: [11, 12],
11: [13]
}
def bfs(graph_to_search, start, end):
queue = [[start]]
visited = set()
while queue:
# Gets the first path in the queue
path = queue.pop(0)
# Gets the last node in the path
vertex = path[-1]
# Checks if we got to the end
if vertex == end:
return path
# We check if the current node is already in the visited nodes set in order not to recheck it
elif vertex not in visited:
# enumerate all adjacent nodes, construct a new path and push it into the queue
for current_neighbour in graph_to_search.get(vertex, []):
new_path = list(path)
new_path.append(current_neighbour)
queue.append(new_path)
# Mark the vertex as visited
visited.add(vertex)
print bfs(graph, 1, 13)
कार्यक्रम का आउटपुट होगा:
[1, 4, 7, 11, 13]
अनसुलझे रिकॉर्क्स के बिना ..
'queue' के लिए 'collects.deque' का उपयोग सूची.pop (0) के रूप में' ओ (एन) 'स्मृति आंदोलनों के रूप में करने के लिए उपयोगी हो सकता है। इसके अलावा, वंशावली के लिए, यदि आप डीएफएस करना चाहते हैं तो बस 'path = queue.pop()' सेट करें, जिस स्थिति में परिवर्तनीय 'कतार' वास्तव में 'स्टैक' की तरह कार्य करता है। – Sudhi
मुझे @Qiao पहले उत्तर और @ या इसके अतिरिक्त दोनों पसंद हैं। थोड़ी कम प्रसंस्करण के लिए मैं यार के जवाब में जोड़ना चाहता हूं।
@ या उत्तर में आने वाले नोड का ट्रैक रखने में बहुत अच्छा है। हम कार्यक्रम को जल्द से जल्द बाहर निकलने की अनुमति भी दे सकते हैं। लूप में किसी बिंदु पर current_neighbour को end होना होगा, और एक बार ऐसा होता है कि सबसे छोटा रास्ता मिलता है और प्रोग्राम वापस आ सकता है।
मैं, इस प्रकार विधि को संशोधित उत्पादन पाश
के लिए पर अधिक ध्यान देंgraph = {
1: [2, 3, 4],
2: [5, 6],
3: [10],
4: [7, 8],
5: [9, 10],
7: [11, 12],
11: [13]
}
def bfs(graph_to_search, start, end):
queue = [[start]]
visited = set()
while queue:
# Gets the first path in the queue
path = queue.pop(0)
# Gets the last node in the path
vertex = path[-1]
# Checks if we got to the end
if vertex == end:
return path
# We check if the current node is already in the visited nodes set in order not to recheck it
elif vertex not in visited:
# enumerate all adjacent nodes, construct a new path and push it into the queue
for current_neighbour in graph_to_search.get(vertex, []):
new_path = list(path)
new_path.append(current_neighbour)
queue.append(new_path)
#No need to visit other neighbour. Return at once
if current_neighbour == end
return new_path;
# Mark the vertex as visited
visited.add(vertex)
print bfs(graph, 1, 13)
और बाकी सब कुछ एक ही होगा होगा। हालांकि, कोड को संसाधित करने में कम समय लगेगा। यह बड़े ग्राफ पर विशेष रूप से उपयोगी है। मुझे उम्मीद है कि यह भविष्य में किसी की मदद करेगा।
यह वास्तव में एक पुराना असाइनमेंट था जिसे मैं केविन बेकन लॉ के आधार पर महीनों पहले एक दोस्त की मदद कर रहा था। मेरा अंतिम समाधान बहुत मैला था, मैंने मूल रूप से एक और ब्रेडथ-पहली खोज "रिवाइंड" और बैकट्रैक करने के लिए की थी। मुझे एक बेहतर समाधान नहीं मिला। –
उत्कृष्ट। मैं एक इंजीनियर में एक प्रशंसनीय विशेषता होने के बेहतर जवाब खोजने के प्रयास में पुरानी समस्या का पुनरीक्षण करने पर विचार करता हूं। मैं आपकी पढ़ाई और करियर में अच्छी तरह से कामना करता हूं। –
प्रशंसा के लिए धन्यवाद, मुझे विश्वास है कि अगर मैं इसे अभी नहीं सीखता, तो मुझे एक ही समस्या का सामना करना पड़ेगा। –