16
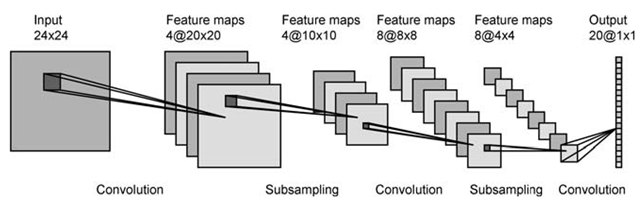
मैं कुछ किताबें और Convolutional तंत्रिका नेटवर्क के बारे में लेख पढ़ा, ऐसा लगता है मैं अवधारणा को समझने लेकिन मैं नहीं जानता कि यह कैसे नीचे छवि में की तरह प्रस्तुत करने के लिए: alt text http://what-when-how.com/wp-content/uploads/2012/07/tmp725d63_thumb.pngकनवॉल्यूशनल तंत्रिका नेटवर्क - फीचर मैप्स कैसे प्राप्त करें?
{kind=link}
28x28 सामान्यीकृत पिक्सेल इनपुट से हम 4 मिल आकार 24x24 के फीचर नक्शे। लेकिन उन्हें कैसे प्राप्त करें? INPUT छवि का आकार बदलना? या छवि परिवर्तन प्रदर्शन? लेकिन किस प्रकार के परिवर्तन? या इनपुट छवि को आकार 4x24 के 4 टुकड़ों में 4 कोने में काट रहा है? मैं प्रक्रिया को समझ नहीं पा रहा हूं, मेरे लिए ऐसा लगता है कि वे छवि को प्रत्येक चरण में छोटी छवियों में काट या आकार बदलते हैं। कृपया धन्यवाद मदद करें।
क्या आप कनवॉल्यूशनल तंत्रिका नेटवर्क के लिए पढ़ी गई पुस्तकों/लेखों की गणना कर सकते हैं? अग्रिम में धन्यवाद। – lmsasu
यह तंत्रिका नेटवर्क और लर्निंग मशीनों से है, तीसरी संस्करण पुस्तक –
मैं भी उलझन में था, यह संकल्प वास्तव में बहुत महत्वपूर्ण हिस्सा है (इसलिए नाम 'संकल्पक एनएन') है, लेकिन ज्यादातर लोग यह समझाने पर ध्यान केंद्रित करते हैं कि सीएनएन कैसे काम करता है, और "फीचर मैप्स कैसे प्राप्त करें" भाग को अनदेखा करें। जब तक मुझे यह वेबसाइट नहीं मिली, तब तक मैं उलझन में था (और गुस्से में भी): http://www1.i2r.a-star.edu.sg/~irkhan/conn2.html यह सादे अंग्रेजी में सबकुछ बताता है। –