एनवीआईडीआईए मेमोरी ट्रांसफर ओवरहेड्स को कम करने के लिए GPUDirect प्रदान करता है। मैं सोच रहा हूं कि एएमडी/एटीआई के लिए एक समान अवधारणा है या नहीं? विशेष रूप से:क्या एएमडी का ओपनसीएल सीयूडीए के जीपीयूड्रैक्ट के समान कुछ ऑफर करता है?
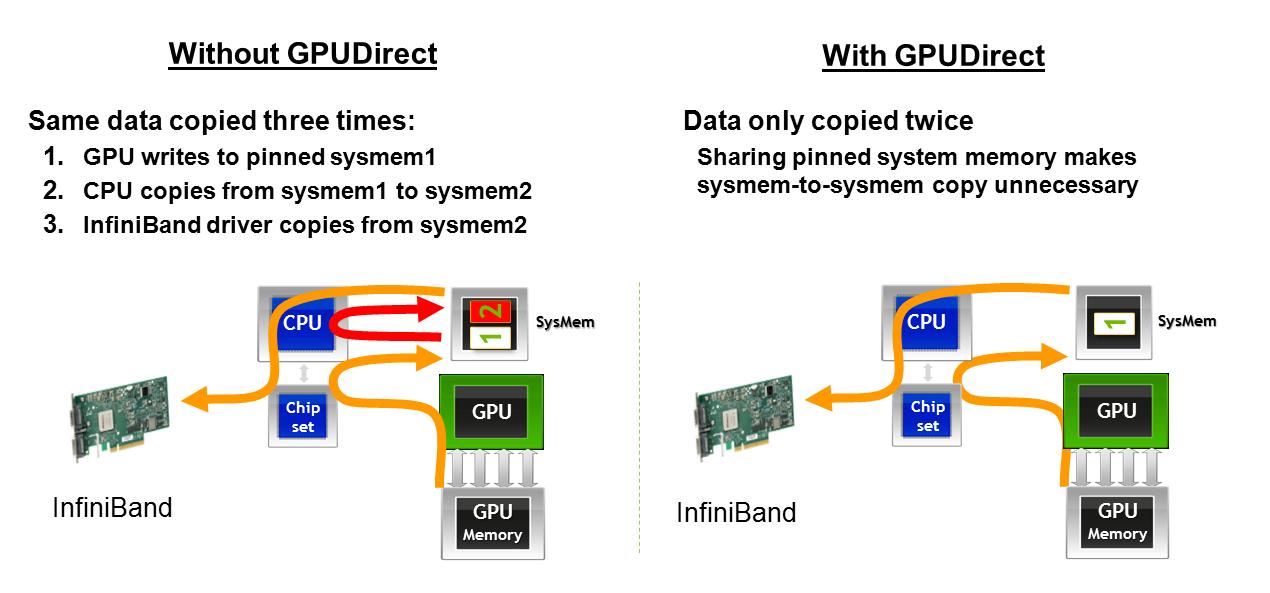
1) एएमडी GPUs जब नेटवर्क कार्ड, as described here साथ इंटरफ़ेस दूसरा स्मृति हस्तांतरण से बचने के है। यदि किसी बिंदु पर ग्राफ़िक खो जाता है, तो एक नेटवर्क पर एक जीपीयू से डेटा प्राप्त करने पर GPUDirect के प्रभाव का वर्णन यहां एक नेटवर्क इंटरफ़ेस में स्थानांतरित किया जा सकता है: GPUDirect के साथ, GPU मेमोरी मेमोरी होस्ट करने के लिए सीधे नेटवर्क पर जाती है इंटरफ़ेस कार्ड GPUDirect के बिना, जीपीयू मेमोरी एक एड्रेस स्पेस में मेमोरी होस्ट करने के लिए जाती है, तो सीपीयू को मेमोरी को किसी अन्य होस्ट मेमोरी एड्रेस स्पेस में लाने के लिए एक प्रतिलिपि करना पड़ता है, फिर यह नेटवर्क कार्ड पर जा सकता है।
{kind=link}
2) जब दो GPUs ही PCIe बस, as described here पर साझा कर रहे हैं AMD GPUs पी 2 पी स्मृति स्थानान्तरण की अनुमति देते हैं। यदि किसी बिंदु पर ग्राफ़िक खो जाता है, तो यहां एक ही पीसीआईई बस पर जीपीयू के बीच डेटा स्थानांतरित करने पर GPUDirect के प्रभाव का विवरण दिया गया है: GPUDirect के साथ, डेटा मेजबान स्मृति को छूए बिना, उसी पीसीआई बस पर GPUs के बीच सीधे स्थानांतरित हो सकता है। GPUDirect के बिना, जीपीयू कहां स्थित है, इस पर ध्यान दिए बिना, डेटा को हमेशा किसी अन्य जीपीयू में आने से पहले होस्ट पर वापस जाना होगा।
{kind=link}
संपादित करें: BTW, मैं नहीं पूरी तरह से यकीन है कि कैसे GPUDirect के बहुत vaporware है हूँ और इसके बारे में कितना वास्तव में उपयोगी है। मैंने वास्तव में कुछ वास्तविक के लिए इसका उपयोग कर एक जीपीयू प्रोग्रामर के बारे में कभी नहीं सुना है। इस पर विचार भी स्वागत है।
आप लिंक किए गए ग्राफिक्स कुछ बाद की तारीख में नीचे रखा जाता है के मामले में दो प्रौद्योगिकियों के एक पाठ विवरण प्रदान कर सकता है? साथ ही, मुझे दूसरी ग्राफिक को अस्पष्ट होने के लिए अस्पष्ट लगता है। – James
जेम्स, यह किया जाता है। – arrayfire
@gpu: mvapich2 के पास हालिया रिलीज में जीपीयू सीधा समर्थन है, मैंने इसका इस्तेमाल किया है और यह वास्तव में तेज़ है - आप 'एमपीआई_Send' और' एमपीआई_रेसीवी 'को कॉल कर सकते हैं और जीपीयू मेमोरी पॉइंटर्स को तर्क के रूप में पास कर सकते हैं और सबकुछ "बस काम करता है"। – talonmies