तरह जीसीसी "-finput-charset = CharSet" मैं कुछ नमूना प्रोग्राम हैं जो एन्कोडिंग के साथ सौदा बनाना चाहते हैं, विशेष रूप से मैं चाहते की तरह विस्तृत तार का उपयोग करें:विशिष्टता,
wstring a=L"grüßen";
wstring b=L"שלום עולם!";
wstring c=L"中文";
क्योंकि ये उदाहरण कार्यक्रम हैं।
यह जीसीसी के साथ बिल्कुल छोटा है जो स्रोत कोड को यूटीएफ -8 एन्कोडेड टेक्स्ट के रूप में मानता है। लेकिन, सीधा संकलन एमएसवीसी के तहत काम नहीं करता है। मुझे पता है कि मैं उन्हें एन्कोड दृश्यों का उपयोग करके एन्कोड कर सकता हूं लेकिन मैं उन्हें पठनीय पाठ के रूप में रखना पसंद करूंगा।
क्या कोई विकल्प है जिसे मैं "cl" के लिए कमांड लाइन स्विच के रूप में निर्दिष्ट कर सकता हूं ताकि इस काम को कर सके? वहां gcc'c -finput-charset
धन्यवाद की तरह किसी भी आदेश पंक्ति स्विच,
यदि नहीं आप कैसे सुझाव है पाठ उपयोगकर्ता के लिए प्राकृतिक होगा?
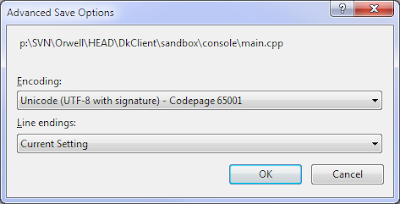
नोट: बीओएम को यूटीएफ -8 फ़ाइल में जोड़ना एक विकल्प नहीं है क्योंकि यह अन्य कंपाइलरों द्वारा गैर-संकलित हो जाता है।
टिप्पणी 2: मैं इसे MSVC संस्करण में काम करने के लिए> = 9 == वी.एस. 2008
असली जवाब की जरूरत है: वहाँ कोई समाधान नहीं
यह वास्तव में आश्चर्यजनक है एमएसवीसी ++ में ऐसे कंपाइलर का विकल्प नहीं है। क्या शर्म की बात है ... –
मुझे लगता है कि आप इस सवाल पूछते समय * स्रोत ** फ़ाइल ** ** वर्णमाला * का विनिर्देशन का मतलब है। * स्रोत वर्णसेट * मानक में टर्मिनल द्वारा आंतरिक रूप से उपयोग किए जाने वाले कार्यान्वयन परिभाषित वर्णसेट के लिए उपयोग किया जाता है। –
@PiotrDobrogost यह किसी का अनुमान है कि माइक्रोसॉफ्ट ने संकलन और एसडीके के लिए यूटीएफ -8 को मूल रूप से समर्थन देकर बाकी दुनिया के साथ क्यों नहीं पकड़ा है, और प्रोग्रामर के जीवन में इतनी अक्षमता, परेशानी, भ्रम और दुःख जोड़ना है जो विंडोज अनुप्रयोगों को अंतर्राष्ट्रीय बनाना चाहिए एक यूटीएफ -8 दुनिया में। लेकिन मुझे लगता है; इसे गुणवत्ता के लिए देखभाल या चिंता पर * नौकरशाही * और * लाभ-उद्देश्य * कहा जाता है। –